1.4. Manipulación de dataframes#
Introducción#
Como vimos brevemente en la unidad anterior, los dataframes son una estructura de datos bidimensional (filas y columnas) similar a una hoja de cálculo o tabla SQL. Se compone de:
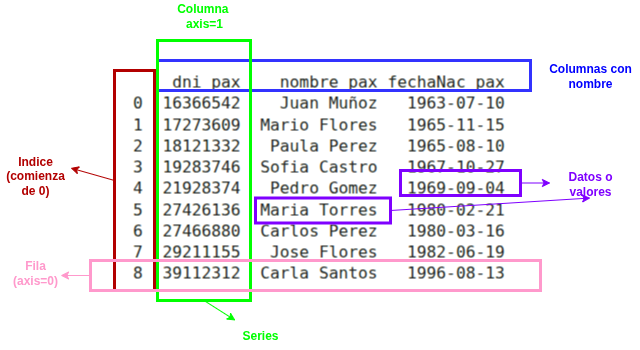
En esta parte veremos algunos métodos útiles para manipular esta estructura sumamente necesaria para la analítica de datos.
Creación de dataframes#
MOMENTO CHEATSHEET
Este es el momento de recurrir a otra parte de la cheatsheet que provee un resumen breve y práctico de información clave sobre la creación de dataframes en Pandas. Mostramos en la figura siguiente la parte que nos interesa en este momento.

Para crear un dataframe debemos definir el nombre de las columnas (
axis=1) y las filas (axis=0):
import pandas as pd
#Creamos el DF con un arreglo y el nombre de las columnas
df1 = pd.DataFrame([1,2,3,4], columns = ['col1'])
df1
| col1 | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
# ahora con dos columnas
df2 = pd.DataFrame([[1,2],[3,4]], columns = ['col1','col2'])
df2
| col1 | col2 | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
# ahora con dos columnas y un indice modificado con letras
df3 = pd.DataFrame([[1,2],[3,4]], columns = ['col1','col2'], index = ['A','B'])
df3
| col1 | col2 | |
|---|---|---|
| A | 1 | 2 |
| B | 3 | 4 |
También podemos crear un
dataframeenviando undictionaryde datos:
# creo un dict con un valor
mi_dict = { "id" : [1], "nombre" : ["Juan"], "apellido" : ["Perez"], "edad" : [25]}
print(mi_dict)
#creo el DF en base al dict
df4 = pd.DataFrame(mi_dict)
df4
{'id': [1], 'nombre': ['Juan'], 'apellido': ['Perez'], 'edad': [25]}
| id | nombre | apellido | edad | |
|---|---|---|---|---|
| 0 | 1 | Juan | Perez | 25 |
# ahora un dict con un arreglo de valores
mi_dict = { "id" : [1,2,3],
"nombre" : ["Elena","Inés", "Elsa"],
"apellido" : ["Nito", "Table", "Pato"],
"edad" : [25,35,45]}
print(mi_dict)
#creo el DF en base al dict
df4 = pd.DataFrame(mi_dict)
df4
{'id': [1, 2, 3], 'nombre': ['Elena', 'Inés', 'Elsa'], 'apellido': ['Nito', 'Table', 'Pato'], 'edad': [25, 35, 45]}
| id | nombre | apellido | edad | |
|---|---|---|---|---|
| 0 | 1 | Elena | Nito | 25 |
| 1 | 2 | Inés | Table | 35 |
| 2 | 3 | Elsa | Pato | 45 |
Acceso a filas y columnas#
Ahora vamos a describir como manipular estos dataframes. Lo podemos hacer directamente por el nombre de la/s columna/s.
Un corchete o dos?
El uso de uno o dos corchetes tiene un significado diferente:
df['nombrecolumna']: selecciona la columna y devuelve unaSeriedf[['nombrecolumna']]: selecciona la columna y devuelve unDataFrame. Puede ser también con más de una columna,df[['col1','col2']]
Si queremos seleccionar filas y/o columnas por su nombre o índice, hacemos:
#selecciono la columna nombre con un corchete y devuelve Series
print(f'La columna nombre con un corchete es \n{df4["nombre"]} y es del tipo {type(df4["nombre"])}')
print('=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=')
#selecciono la columna nombre con dos corchete y devuelve DF
print(f'La columna nombre con dos corchetes es \n{df4[["nombre"]]} y es del tipo {type(df4[["nombre"]])}')
La columna nombre con un corchete es
0 Elena
1 Inés
2 Elsa
Name: nombre, dtype: object y es del tipo <class 'pandas.core.series.Series'>
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
La columna nombre con dos corchetes es
nombre
0 Elena
1 Inés
2 Elsa y es del tipo <class 'pandas.core.frame.DataFrame'>
#selecciono la columna nombre con dos corchetes y devuelve DF
print(f"""La columna nombre y apellido con dos corchetes es \n{df4[["nombre","apellido"]]}
y es del tipo {type(df4[["nombre","apellido"]])}""")
La columna nombre y apellido con dos corchetes es
nombre apellido
0 Elena Nito
1 Inés Table
2 Elsa Pato
y es del tipo <class 'pandas.core.frame.DataFrame'>
Uso de .loc[ ] e .iloc[ ]#
Ademas, hay dos métodos muy útiles para seleccionar datos de un dataframe: .loc[] e .iloc[].
MOMENTO CHEATSHEET
Este es el momento de recurrir a otra parte de la cheatsheet que provee un resumen breve y práctico de información clave sobre los métodos .loc[] e .iloc[]. Mostramos en la figura siguiente la parte que nos interesa en este momento.

Usos de .loc[] e iloc[]
Los métodos mas importantes para seleccionar filas y columnas en dataframes son:
df.loc[fila(s), columna(s)]: para seleccionar y acceder a filas y columnas por etiquetas (no por posición numérica)fila(s): etiqueta(s) o condición para las filas. Se puede usar el valor delindex.columna(s): etiqueta(s) o condición para las columnas.
df.iloc[fila(s), columna(s)]: para seleccionar y acceder a filas y columnas por posición numérica. No se puede utilizar para agregar nuevas filas a undataframe.fila(s): índice o rango numérico de filas. No es el valor delindex.columna(s): índice o rango numérico de columnas.
Veamos algunos ejemplos con
.loc[]:
# vemos que tenia df4
df4
| id | nombre | apellido | edad | |
|---|---|---|---|---|
| 0 | 1 | Elena | Nito | 25 |
| 1 | 2 | Inés | Table | 35 |
| 2 | 3 | Elsa | Pato | 45 |
#selecciono usando .loc[] y usando el indice 0 y todas las columnas
# que es lo mismo a df4.loc[0,:].
# El : define rangos en listas, tuplas o arrays inicio:fin, el : solo selecciona TODO
print(f'La primera fila es: \n{df4.loc[0]}')
print('=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=')
# seleccionamos la primera fila y la columna nombre
print(f'El nombre de la primera fila es: {df4.loc[0,"nombre"]}')
print('=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=')
# seleccionamos los nombres y apellidos de las personas con mas de 30 años
print(f'El nombre y apellido de las personas con mas de 30 años son: \n {df4.loc[df4["edad"]>30, ["nombre","apellido"]]}')
La primera fila es:
id 1
nombre Elena
apellido Nito
edad 25
Name: 0, dtype: object
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
El nombre de la primera fila es: Elena
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
El nombre y apellido de las personas con mas de 30 años son:
nombre apellido
1 Inés Table
2 Elsa Pato
Veamos algunos ejemplos con
.iloc[]:
# seleccionando usando .iloc[]
print(f'La primera fila es: \n{df4.iloc[0]}')
print('=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=')
# seleccionamos la primera fila y la columna nombre, nombre esta en el subindice 1
print(f'El nombre de la primera fila es: {df4.iloc[0,1]}')
print('=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=')
# seleccionamos todas las filas y probamos la condicion de mas de 30 años
print(f'Las filas que cumplen con la condición de tener mas de 30 años son: \n{df4.iloc[:,3]>30}')
print('=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=')
#uso el filtro anterior para la consulta del nombre y apellido de las personas con mas de 30 años
filtro = df4.iloc[:,3]>30
df5 = df4[filtro]
print(f'Con el filtro anterior me queda: \n{df5}')
# ahora si selecciono solo el nombre y apellido
print(f'El nombre y apellido de las personas con mas de 30 años son: \n{df5.iloc[:,1:3]}')
La primera fila es:
id 1
nombre Elena
apellido Nito
edad 25
Name: 0, dtype: object
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
El nombre de la primera fila es: Elena
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
Las filas que cumplen con la condición de tener mas de 30 años son:
0 False
1 True
2 True
Name: edad, dtype: bool
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
Con el filtro anterior me queda:
id nombre apellido edad
1 2 Inés Table 35
2 3 Elsa Pato 45
El nombre y apellido de las personas con mas de 30 años son:
nombre apellido
1 Inés Table
2 Elsa Pato
Tanto el .loc[] como el .iloc[] se pueden usar también para asignar y cambiar valores.
Vamos a crear un nuevo
dataframe:
# un nuevo dataframe de un dict
mi_dict = { "id" : [4,5,6],
"nombre" : ["Armando","Esteban", "Justin"],
"apellido" : ["Casas", "Quito ", "Case"],
"edad" : [20,30,40]}
print(mi_dict)
#creo el DF en base al dict
df5 = pd.DataFrame(mi_dict)
df5
{'id': [4, 5, 6], 'nombre': ['Armando', 'Esteban', 'Justin'], 'apellido': ['Casas', 'Quito ', 'Case'], 'edad': [20, 30, 40]}
| id | nombre | apellido | edad | |
|---|---|---|---|---|
| 0 | 4 | Armando | Casas | 20 |
| 1 | 5 | Esteban | Quito | 30 |
| 2 | 6 | Justin | Case | 40 |
Unimos df4 con df5 (lo hacemos con
concatque apila dosdataframes):
# apilo df4 con df5 (por defecto aplica filas axis=0)
# y lo hacemos para que cree un nuevo indice del 0 al 5
df_unido = pd.concat([df4, df5], ignore_index=True)
df_unido
| id | nombre | apellido | edad | |
|---|---|---|---|---|
| 0 | 1 | Elena | Nito | 25 |
| 1 | 2 | Inés | Table | 35 |
| 2 | 3 | Elsa | Pato | 45 |
| 3 | 4 | Armando | Casas | 20 |
| 4 | 5 | Esteban | Quito | 30 |
| 5 | 6 | Justin | Case | 40 |
Ahora cambiamos las edades y sumamos 1 a todo:
#lo converti a entero
df_unido.loc[:,"edad"] = df_unido.loc[:,"edad"].astype("int")
#df_unido.dtypes
df_unido
#le sumo 1 a todas las edades
df_unido.loc[:,"edad"] = df_unido["edad"]+1
df_unido
| id | nombre | apellido | edad | |
|---|---|---|---|---|
| 0 | 1 | Elena | Nito | 26 |
| 1 | 2 | Inés | Table | 36 |
| 2 | 3 | Elsa | Pato | 46 |
| 3 | 4 | Armando | Casas | 21 |
| 4 | 5 | Esteban | Quito | 31 |
| 5 | 6 | Justin | Case | 41 |
Uso de archivos .csv#
El uso de archivos .csv es muy útil en análisis de datos ya que permite importarlos y trabajarlos con Pandas, o exportarlos y utilizarlos en el futuro.
QUÉ SON LOS ARCHIVOS .csv?
Un archivo .csv (comma-separated values) es un archivo de texto sin formato que simplifica el almacenamiento y la transferencia de datos. Almacena los datos en formato tabular, donde cada fila representa un registro y cada columna está separada por una coma (u otro caracter a elección).

Su estructura es sencilla y plana lo que permite una transferencia de datos rápida y flexible entre sistemas. A su vez, posee compatibilidad con una amplia gama de herramientas de software.
Los archivos .csv se utilizan principalmente para el intercambio, análisis y gestión de datos.
Exportación de datos a .csv#
Pandas posee el método .to_csv() que permite transformar un dataframe a un archivo .csv.
PARÁMETROS DEL MÉTODO .to_csv() de Pandas
El método .to_csv() es muy flexible ya que permite controlar varias opciones para la creación de estos archivos como el delimitador, codificación, nombres de columnas, formato, compresión, etc. Algunos de sus parámetros son:
path_or_buf: Nombre del archivo, puede ir toda la rutasep: Separador de columnas (por defecto ‘,’)index: Escribir índice como columna (Truepor defecto)columns: Lista de columnas a escribirheader: Incluir nombre de columnas (Truepor defecto)encoding: Tipo de codificación a utilizar (‘utf-8’, ‘utf-8-sig’, ‘latin-1’, etc.)na_rep: Representación para valores nulos (por ejemplo ‘NULL’, ‘-’, etc.). Por defecto usa un string vaciodecimal: Caracter para los números con decimales (‘.’ o ‘,’)compression: Comprime el archivo (‘gzip’, ‘zip’, ‘bz2’, ‘xz’)date_format: Formato de fechas (por ejemplo ‘%Y-%m-%d’)float_format: Formato de floats (ej: ‘%.2f’)
Toda la información la podemos encontrar aca pandas.DataFrame.to_csv
Si queremos exportar el
dataframe df_unido, a continuación hay opciones del método que crea diferentes archivos llamadosdatos_unidosXXX.csvy se guardan en la carpeta archivosGenerados (crear una carpeta llamada archivosGenerados):
#con las opciones por defecto
df.to_csv('archivosGenerados/datos_unidosPorDefecto.csv')
# sin indice
df.to_csv('archivosGenerados/datos_unidosCambios.csv', index=False)
#sin indice y con separador entre datos
df.to_csv('archivosGenerados/datos_unidosCambios2.csv', index=False, sep='#')
# con indice y nombre de las columnas que queremos incluir
df.to_csv('archivosGenerados/datos_unidosCambios3.csv', index=True, columns=['nombre', 'apellido'])
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[14], line 2
1 #con las opciones por defecto
----> 2 df.to_csv('archivosGenerados/datos_unidosPorDefecto.csv')
4 # sin indice
5 df.to_csv('archivosGenerados/datos_unidosCambios.csv', index=False)
NameError: name 'df' is not defined
Importación de .csv a dataframes#
Pandas posee también el método .read_csv() que permite leer un archivo .csv y transformarlo en un dataframe.
PARÁMETROS DEL MÉTODO .read_csv() de Pandas
El método .read_csv() permite leer un archivo de este tipo y guardarlo en un dataframe. Algunos de sus parámetros son:
filepath_or_buf: Nombre del archivo, puede ir toda la rutasep: Separador de columnas (por defecto ‘,’)header: indica si la primera fila se usa como cabecera. Por defecto es 0, que significa sinames: lista con los nombres de columnas (se usa conheader=Noneo para renombrar)na_values: lista indica que valores de los datos se deben considerar comoNaNusecols: lista las columnas específicas a leer del archivo
Toda la información la podemos encontrar aca pandas.read_csv
Vemos ejemplos de archivos obtenidos de https://datos.gob.ar/dataset. Los mismos estan en archivos csv
Bajamos el archivo maiz-serie-1923-2023-anual.csv y lo copiamos en una carpeta llamada _ archivos_datasets_ de mi máquina local.
Leemos de la carpeta creada:
#leo y paso a DF el archivo completo
df_maiz = pd.read_csv('archivos_datasets/maiz-serie-1923-2023-anual.csv')
df_maiz
| indice_tiempo | superficie_sembrada_maiz_ha | superficie_cosechada_maiz_ha | produccion_maiz_t | rendimiento_maiz_kgxha | |
|---|---|---|---|---|---|
| 0 | 1923 | 3435430 | NaN | 7030000 | NaN |
| 1 | 1924 | 3707700 | 2911768.0 | 4732235 | 1421.29 |
| 2 | 1925 | 4297000 | 3898912.0 | 8170000 | 1788.59 |
| 3 | 1926 | 4289000 | 3666650.0 | 8150000 | 1741.61 |
| 4 | 1927 | 4346000 | 3641826.0 | 7915000 | 1789.96 |
| ... | ... | ... | ... | ... | ... |
| 96 | 2019 | 9504473 | 7730506.0 | 58395811 | 6820.61 |
| 97 | 2020 | 9742230 | 8146596.0 | 60525805 | 6428.21 |
| 98 | 2021 | 10670126 | 8768441.0 | 59037179 | 5776.59 |
| 99 | 2022 | 10533195 | 8104641.0 | 41409448 | 4583.40 |
| 100 | 2023 | 11103250 | 8736712.0 | 57494500 | 5413.19 |
101 rows × 5 columns
#leo y paso a DF solo las columnas indice_tiempo y superficie_sembrada_maiz_ha
df_maiz = pd.read_csv('archivos_datasets/maiz-serie-1923-2023-anual.csv',
usecols = ['indice_tiempo','superficie_sembrada_maiz_ha'] )
df_maiz
| indice_tiempo | superficie_sembrada_maiz_ha | |
|---|---|---|
| 0 | 1923 | 3435430 |
| 1 | 1924 | 3707700 |
| 2 | 1925 | 4297000 |
| 3 | 1926 | 4289000 |
| 4 | 1927 | 4346000 |
| ... | ... | ... |
| 96 | 2019 | 9504473 |
| 97 | 2020 | 9742230 |
| 98 | 2021 | 10670126 |
| 99 | 2022 | 10533195 |
| 100 | 2023 | 11103250 |
101 rows × 2 columns