1.2. Datos semi-estructurados#
Introducción#
Los datos semi-estructurados poseen cierta organización, pero sin cumplir reglas estrictas como los estructurados. Ejemplos de estos datos son archivos XML, JSON, algunos archivos de logs, archivos HTML, etc.
Los datos semi-estructurados generalmente provienen de la web, logs, mails, sensores, etc.

La Web es considerada semi-estructurada ya que define un lenguage de marcado llamado HTML cuya función es describir la estructura y el contenido de una página web. Los navegadores (como Chrome, Firefox, Edge, Safari) leen HTML para saber qué mostrar y cómo organizar el contenido.
Las elementos mas destacados del lenguaje HTML son:
Etiquetas (Tags): Son la base de HTML. Cada etiqueta define un tipo de contenido o estructura. Ejemplo:
<h1>Un título</h1>
<p>Un párrafo</p>
Elementos: Pueden estar anidados e incluyen una etiqueta de apertura, contenido, y una etiqueta de cierre. El elemento
<html>es considerado raiz. Debe iniciar con<html>y finalizar con</html>. Existen otros elementos como:<body>,<h1>y<p>.Atributos: Proveen información adicional de los elementos. Siempre se especifican en el tag de inicio y se escriben de la forma
nombre-"valor". Ejemplos:<a href=”http://www.HOLA.com”> Visitar HOLA</a>
<img src=”mi_imagen.jpg” alt=”Es una imagen de la playa”>
Hay muchas páginas que enseñan el lenguaje HTML. Por ejemplo:
W3C HTML: describe todos los componentes
HTMLcon ejemplos que se pueden ejecutar.FreeCodeCamp: provee una breve introducción a los fundamentos del lenguaje
HTMLcon ejemplos simples.
Pero nosotros no debemos hacernos expertos en el lenguaje, sólo debemos poder leerlo para extraer información útil para poder estructurarla.
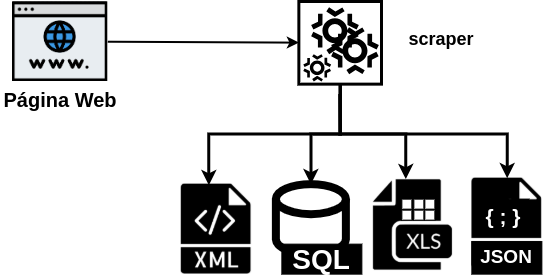
Web scraping#
Un scraper es un programa que se centra en extraer datos específicos de los sitios Web y exportarlos para un almacenamiento en formato XML, Excel, JSON o SQL. Su automatización permite recopilar datos para aplicar luego análisis sobre los mismos.
Librerías a utilizar:
Requests: para realizar requerimientos HTTP (HTTP requests).
Urllib: similar a
requests, pero es nativo de python y un poco menos intuituvo.BeautifulSoup: para analizar (parsing) HTML y extraer los datos.
Comenzamos importando las librerías:
import requests
from bs4 import BeautifulSoup
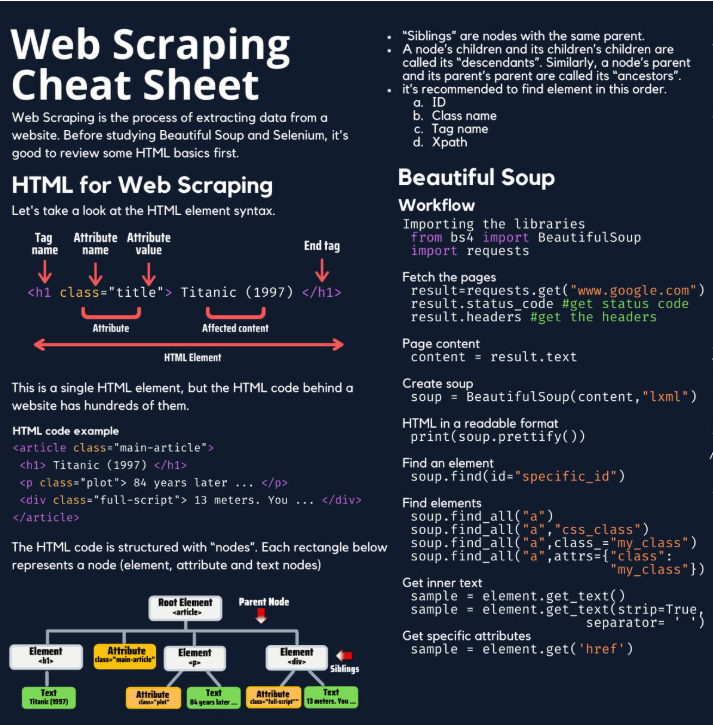
MOMENTO CHEATSHEET
Este es el momento de recurrir a una cheatsheet que provea un resumen breve y práctico de información clave sobre esas librerías.
Uso del requests#
Vamos con un ejemplo simple de un HTML de laboratorio.
Ingresar a la url Aerolineas. Podemos también inspeccionar su código HTML desde el navegador.
Comenzamos indicando el
urlde donde esta ubicada la páginaaerolineas.html
# indico sobre la URL.
url = 'https://cursoepa.fi.uncoma.edu.ar/archivos_datasets/aerolineas.html'
# los headers son necesarios para que no nos rechace la conexión.
headers = {"User-Agent": "Mozilla/5.0"}
# realizo el request
resultado = requests.get(url, headers=headers)
# Fuerza la codificación a UTF-8 (para acentos y caracteres especiales)
resultado.encoding = 'utf-8'
Podemos ver la respuesta obtenida en formato texto con resultado.text. En esa variable tenemos todo el HTML de la página en formato texto. Podemos imprimir solo algunos caracteres.
html_respuesta=resultado.text
# devuelvo el HTML como respuesta (desde el caracter 700 al 1500)
print(html_respuesta[675:1000])
<h1>Información de Vuelos - Aerolínea Casi A Tiempo Air</h1>
<table>
<thead>
<tr>
<th data-code="nro_vue">N° de Vuelo</th>
<th data-code="tipo_vue">Tipo de Vuelo</th>
<th data-code="origen_vue">Origen</th>
<th data-code="fechaS_vue">Fecha de Salida</th>
<th data-code="h
Uso de beautifulSoup#
Para comenzar a trabajar con la librería BeautifulSoup debemos definir una variable que posea el código HTML recuperado.
Entonces, creamos una variable
soupcon el contenido dehtml_respuesta:
soup = BeautifulSoup(html_respuesta, 'lxml')
#print(soup.prettify())
Método find()
El método find() se utiliza cuando existe sólo un elemento que coincida con los criterios de búsqueda o si solo se desea el primero, ya que devuelve el primer elemento que coincida.
Ahora podemos probar obtener el elemento
h1, es decir la primera etiqueta <h1> en la páginaHTML:
h1text = soup.find("h1")
h1text
<h1>Información de Vuelos - Aerolínea Casi A Tiempo Air</h1>
Método find_all()
El método find_all() se utiliza cuando existen varios elementos que coinciden con los criterios de búsqueda. Devuelve un ResultSet. Este tipo de datos se utiliza generalmente para las respuestas de las BDs. Vamos a usar sólo su método get() para obtener elementos dentro del mismo.
Podemos probar obtener todas las etiquetas <th> de la página
HTML, e imprimimos el tipo de la respuesta:
resultado_th = soup.find_all("th")
print(type(resultado_th))
<class 'bs4.element.ResultSet'>
Un vez que tenemos el resultado podemos realizar operaciones para manipularlo.
Primero iteramos sobre el resultado
resultado_the imprimimos cada elemento:
for elemento in resultado_th:
print(elemento)
<th data-code="nro_vue">N° de Vuelo</th>
<th data-code="tipo_vue">Tipo de Vuelo</th>
<th data-code="origen_vue">Origen</th>
<th data-code="fechaS_vue">Fecha de Salida</th>
<th data-code="horaS_vue">Hora de Salida</th>
<th data-code="destino_vue">Destino</th>
<th data-code="fechaA_vue">Fecha de Arribo</th>
<th data-code="horaA_vue">Hora de Arrivo</th>
<th data-code="matricula_avi">Matrícula del Avión</th>
<th data-code="descripcion">Descripción del vuelo</th>
Como vemos, cada elemento es un nodo completo donde inicia y termina la etiqueta <th>…</th>.
Ahora vamos a recuperar todas las etiquetas <td> y listar sólo las primeras 10:
resultado_td = soup.find_all("td")
#imprimo solo los primeros 10 elementos donde inicio y termina un nodo <td>....</td>
print(resultado_td[0:10])
[<td data-code="nro_vue">AL0025
</td>, <td data-code="tipo_vue">Cabotaje
</td>, <td data-code="origen_vue">COM
</td>, <td data-code="fechaS_vue">2024-02-16
</td>, <td data-code="horaS_vue">21:00:00
</td>, <td data-code="destino_vue">BUE
</td>, <td data-code="fechaA_vue">2024-02-16
</td>, <td data-code="horaA_vue">23:15:00
</td>, <td data-code="matricula_avi">LV-BYY
</td>, <td data-code="descripcion">El avíón despegó bien, pero tuvo que bajar en NQN porque el baño no funcionaba. LLegó tarde, pero poco.
</td>]
Dataframes#
Luego, así como hicimos con los datos estructurados, debemos pasar esta información a un dataframe para poder manipularlo facilmente.
Recordando dataframes
Los dataframes son estructuras tipo tabla, donde cada columna (column) representa el índice del eje 1 (axis=1) y son de tipo Series.
Para ponerle un nombre a las columnas del
dataframedebemos recorrer las etiquetas <th> (ya guardadas enresultado_th) y obtener eldata-codede cada una. Luego armar una lista de nombres de columnas:
columnas=[]
for elemento in resultado_th:
columnas.append(elemento.get("data-code"))
columnas
['nro_vue',
'tipo_vue',
'origen_vue',
'fechaS_vue',
'horaS_vue',
'destino_vue',
'fechaA_vue',
'horaA_vue',
'matricula_avi',
'descripcion']
Primero vamos a crear un dataframe solo con las columnas (debemos importar pandas, no lo hicimos antes):
import pandas as pd
#creo un dataframe vacio con los nombres de las columnas que ya tenia
df = pd.DataFrame([], columns=columnas)
df
| nro_vue | tipo_vue | origen_vue | fechaS_vue | horaS_vue | destino_vue | fechaA_vue | horaA_vue | matricula_avi | descripcion |
|---|
Ahora tenemos buscar y armar cada una de las filas. Para eso debemos recuperar el contenido de cada etiqueta <td>.
Volvemos a utilizar
resultado_tdque posee todas las etiquetas completas <td> y recuperamos su texto:
%%script echo 'No lo ejecuto aca porque es muy largo'
for texto in resultado_td:
#imprimo el texto de cada fila <td>
print(texto.get_text())
No lo ejecuto aca porque es muy largo
Una vez que ya podemos obtener los textos de cada fila de etiquetas <td> debemos crear las filas del dataframe. Para esto sabemos que van de 10 en 10 ya que hay 10 columnas. Entonces debemos hacer varias iteraciones.
Iteramos sobre el arreglo
resultado_tdnuevamente y armamos las filas con 10 valores, hasta llegar al final. Usamos también el tipoTuplepara armar eldataframe:
# el tamaño de resultado_td me brinda las iteraciones que debo hacer
# en este caso el tamaño es de 50, lo divido en 10, con lo que debo iterar 5 veces.
#en este caso cantidad vale 50
cantidad = len(resultado_td)
#lo paso a entero porque no puede iterar sobre float
# cantidad_de_a_10/10 es igual a 5
cantidad_de_a_10 = round(cantidad/10)
#creo un tipo de dato tupla para ir guardando cada fila
mis_tuplas = []
#inicializo indice con 1 para ir armando la fila
# va a iiciar en 0 y va a terminar con el valor 50
indice = 0
#el for lo va a hacer 5 veces
for x in range(cantidad_de_a_10):
#cada vez que termina de hacer un fila con 10 valores, se reinicia a vacia
fila=[]
# el for lo hace 10 veces, una por cada columna
for n in range(10):
#armo la fila para luego transformar, desde 0 hasta 50
valor = resultado_td[indice].get_text()
#como el texto lo genera con caracteres en blanco y otras cosas, lo limpio
#es un str, asi que puedo usar las operaciones conocidas
#saco espacios en blanco al inicio y al final del valor
valor = valor.strip()
fila.append(valor)
#print("cada fila aca posee: " , valor)
#sumo el indice de a 1 para ir moviendome sobre resultado_td
indice+=1
# aca tengo la lista completa y creo una tupla de cada una
mi_tupla = tuple(fila)
# voy adicionando las tuplas a una lista de tuplas
mis_tuplas.append(mi_tupla)
#print(mis_tuplas)
#creo el dataframe con los nombres de las columnas que ya tenia y las tuplas
df = pd.DataFrame(mis_tuplas, columns=columnas)
#print(df.head(20))
#creamos un .csv como hicimos con los datos estructurados, pero le agregamos la
#codificacion correcta para que reconozca los acentos
df.to_csv('archivosGenerados/datosvuelo.csv')
df
| nro_vue | tipo_vue | origen_vue | fechaS_vue | horaS_vue | destino_vue | fechaA_vue | horaA_vue | matricula_avi | descripcion | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AL0025 | Cabotaje | COM | 2024-02-16 | 21:00:00 | BUE | 2024-02-16 | 23:15:00 | LV-BYY | El avíón despegó bien, pero tuvo que bajar en ... |
| 1 | AT0334 | Cabotaje | NQN | 2024-02-18 | 08:00:00 | BUE | 2024-02-18 | 10:00:00 | LV-CPJ | El avíón despegó con niebla y los pasajeros se... |
| 2 | AP0221 | Cabotaje | SAL | 2024-02-15 | 13:20:00 | NQN | 2024-02-15 | 16:30:00 | LV-GKP | El avíón despegó bien, al llegar habíaviento y... |
| 3 | AT0334 | Cabotaje | NQN | 2024-02-18 | 08:00:00 | BUE | 2024-02-18 | 10:00:00 | LV-CPJ | El avíón despegó con niebla y los pasajeros se... |
| 4 | AV2375 | Cabotaje | COR | 2024-02-14 | 09:20:00 | ROS | 2024-02-14 | 10:00:00 | LV-CPJ | El avíón despegó con lluvia y mucho calor. Se ... |
Vamos a ver otro ejemplo de características un poco diferentes, ya que el HTML es distinto.
Creamos un
HTMLque tiene:
html = """
<div class="Producto">
<ul class="detalles">
<li class="id_producto"><strong>Id:</strong> 1</li>
<li class="nombre"><strong>Nombre:</strong> Reloj</li>
</ul>
</div>
<div class="Producto">
<ul class="detalles">
<li class="id_producto"><strong>Id:</strong> 2</li>
<li class="nombre"><strong>Nombre:</strong> Telefono</li>
</ul>
</div>
"""
Ahora obtenemos el
HTMLcreado en el formato desouppara trabajarlo:
soup = BeautifulSoup(html, 'html.parser')
Recuperamos todas las etiquetas
divque tengas laclass_con el nombre de Producto:
resultado = soup.find_all('div', class_='Producto')
resultado
[<div class="Producto">
<ul class="detalles">
<li class="id_producto"><strong>Id:</strong> 1</li>
<li class="nombre"><strong>Nombre:</strong> Reloj</li>
</ul>
</div>,
<div class="Producto">
<ul class="detalles">
<li class="id_producto"><strong>Id:</strong> 2</li>
<li class="nombre"><strong>Nombre:</strong> Telefono</li>
</ul>
</div>]
Armamos listas para guardar los productos y sus nombres:
# creo listas para guardar id_productos y nombre
productos, nombres = [], []
Recorremos el resultado para obtener las
classinternas:
for elemento in resultado:
#buscamos la etiqueta li y el nombre de la clase, y recuperamos el valor
idproducto = elemento.find('li', class_ = 'id_producto').text
#como me devuelve Id:valor, tengo que sacar la palabra Id: y quedarme solo con el valor
idproducto = idproducto.replace("Id:", "").strip()
nombre = elemento.find('li', class_ = 'nombre').text
#como me devuelve Nombre:valor(Reloj o Telefono), tengo que sacar la palabra Nombre:
#y quedarme solo con el valor
nombre = nombre.replace("Nombre:", "").strip()
#lo voy agregando en una lista
productos.append(idproducto)
nombres.append(nombre)
print(productos)
print(nombres)
['1', '2']
['Reloj', 'Telefono']
Ahora si podemos crear un
dataframecon esos datos:
df_productos = pd.DataFrame({
'idproducto': productos,
'Nombre': nombres
})
df_productos
| idproducto | Nombre | |
|---|---|---|
| 0 | 1 | Reloj |
| 1 | 2 | Telefono |