1.1. Datos estructurados#
Introducción#
Los datos estructurados generalmente provienen de las bases de datos.

Como ya conocen MariaDB vamos a leer datos de una de las bases de datos trabajadas en la asignatura anterior.
Vamos a utilizar las siguientes librerías:
Pandas: para análisis y manipulación de datos.
Mysql connector: para la conexión de entre python y la BD.
Comenzamos importando las librerías:
import pandas as pd
import mysql.connector as mariadb
Conexión#
Comenzamos configurando los parámetros de la conexión, en donde indicamos en qué máquina esta alojada la BD, el puerto, usuario, clave y el nombre de la BD a la cual acceder. En nuestro caso, podemos cambiar el nombre de la BD ('database': 'baseAerolinea') a cualquiera de las disponibles en el sistema gestor.
Creamos el diccionario
db_configcon los siguientes parámetros:
# Crear una estructura que posea todos los datos que necesita una conexion a
# Maria DB y a la BD
db_config = {
'host': '10.0.2.200',
'port': 3306,
'user': 'usuario2',
'password': 'usuario1123',
'database': 'baseAerolinea'
}
El host donde esta instalada MariaDB en este ejemplo es: 10.0.2.200. El mismo representa un host dentro de la red local y el puerto 3306 que se utiliza por defecto con MariaDB.
Sin embargo, se puede reemplazar por el gestor de MariaDB en la Web con los siguientes parámetros:
'host': 'eida-db.fi.uncoma.edu.ar',
'port': 3337,
Para hacer la conexión, usamos el try-except que nos permite manejar las excepciones nosotros mismos.
Luego usamos la estructura anterior y el método
connect(**db_config)para conectarnos con la DB de la aerolinea:
conexion = None
try:
#Establecer la conexion
print("Conectando a MariaDB...")
conexion = mariadb.connect(**db_config)
print("Conexión exitosa!")
# Siempre se debe cerrar la conexion
conexion.close()
print("Conexión a MariaDB cerrada.")
except mariadb.Error as e:
print(f"Ocurrió un error :( {e}")
Conectando a MariaDB...
Conexión exitosa!
Conexión a MariaDB cerrada.
RECORDAMOS…
El ** se usa para extraer todas las claves y valores de un diccionario y pasarlos como argumentos con nombre (kwargs)
Cursores#
Un objeto importante de librería de MySQL es el tipo cursor, ya que permite la ejecución de las consultas y la manipulación de los resultados.
MÉTODOS Y PROPIEDADES DEL CURSOR
Algunos de los métodos y propiedades de los cursores son:
execute(): toma una consulta SQL como parámetro (str) y la ejecutaexecutemany(): permite ejecutar la misma sentencia SQL muchas veces con diferentes parámetros, normalmente paraINSERT,UPDATEoDELETEfetchall(): recupera todas las tuplas del resultado de una consulta y las devuelve como una lista de tuplas:[(..,..,..),(..,..,..)]. Si se ejecuta después de recuperar algunas tuplas, se devuelven las restantes. Si no posee filas devuelve una lista vacía[].fetchone(): recupera la siguiente tupla del resultado de una consulta y la devuelve como una tuplafetchmany(size): recupera el conjunto de tuplas indicado como parámetro. Por ejemplofetchmany(3)recupera una lista de las tres primeras tuplas del resultado de la consulta.close(): Cierra un cursor abiertodescription: Es una propiedad de solo lectura que devuelve una lista de tuplas con las columnas de un conjunto de tuplas. El primer valor de cada tupla de la lista es el nombre de la columna
Un aspecto importante del cursor es que no se puede volver atrás en su recorrido. Una vez que se consumen las filas con fetchone(), fetchmany() o fetchall(), no se puede utilizar o volver a recorrer. Hay que volver a ejecutar la consulta.
Otro aspecto de los cursores es que una vez que se busca la información con un cursor, se debe consumir por completo. Es decir, si hago una consulta que devuelve 200 tuplas, debo recuperar las 200.
La documentación completa de este método la podemos encontrar en The cursor class
Vamos a ir por partes para ir mostrando como recuperar datos y manipularlos. Para eso vamos a sacar el try-except por cuestiones de simplicidad, pero en el código terminado y completo debe quedar.
Ahora vamos a utilizar el método
fetchall()para recuperar el resultado de la consulta SQL de todos los datos de latabla pasajero
#Establecer la conexion
print("Conectando a MariaDB...")
conexion = mariadb.connect(**db_config)
print("Conexión exitosa!")
#Crear un cursor con la conexion
cursor = conexion.cursor()
print("\nSeleccionando datos...")
consulta = "SELECT * FROM pasajero"
#Ejecutar la consulta y guardarla en un cursor
cursor.execute(consulta)
#Colocar a datos_del_pasajero el resultado de buscar todos los valores de la consulta
datos_del_pasajero = cursor.fetchall()
Conectando a MariaDB...
Conexión exitosa!
Seleccionando datos...
Este código deja el cursor abierto y también la conexión con la BD. Luego debemos recordar de cerrar el cursor con cursor.close() y la conexión con conexion.close().
Para imprimir o acceder a las tuplas de la lista creada de
datos_del_pasajero, se debe acceder como cualquier lista, con corchetes:
print('La primera tupla del pasajero es: ', datos_del_pasajero[0])
#hace slicing listando del indice 3 (incluido) al 5 (sin incluir)
print('La cuarta y quinta tupla del pasajero es: ', datos_del_pasajero[3:5])
La primera tupla del pasajero es: ('16366542', 'Juan Muñoz', datetime.date(1963, 7, 10))
La cuarta y quinta tupla del pasajero es: [('19283746', 'Sofia Castro', datetime.date(1967, 10, 27)), ('21928374', 'Pedro Gomez', datetime.date(1969, 9, 4))]
Tambien podemos iterar sobre el resultado de la consulta. Recordemos que el resultado del fetchall() es una lista de tuplas.
Vamos a iterar sobre las tuplas del resultado de los pasajeros:
#lo hago con un for
#cada elemento i es una tupla
# el 0 significa que estamos buscando la primera columna
for i in datos_del_pasajero:
print(i)
print(f'El dni del pasajero es {i[0]}')
('16366542', 'Juan Muñoz', datetime.date(1963, 7, 10))
El dni del pasajero es 16366542
('17273609', 'Mario Flores', datetime.date(1965, 11, 15))
El dni del pasajero es 17273609
('18121332', 'Paula Perez', datetime.date(1965, 8, 10))
El dni del pasajero es 18121332
('19283746', 'Sofia Castro', datetime.date(1967, 10, 27))
El dni del pasajero es 19283746
('21928374', 'Pedro Gomez', datetime.date(1969, 9, 4))
El dni del pasajero es 21928374
('27426136', 'Maria Torres', datetime.date(1980, 2, 21))
El dni del pasajero es 27426136
('27466880', 'Carlos Perez', datetime.date(1980, 3, 16))
El dni del pasajero es 27466880
('29211155', 'Jose Flores', datetime.date(1982, 6, 19))
El dni del pasajero es 29211155
('39112312', 'Carla Santos', datetime.date(1996, 8, 13))
El dni del pasajero es 39112312
Dataframes#
Para poder utilizar todos los beneficios de los dataframes de Pandas, vamos a almacenar el resultado de la consulta en una estructura de este tipo.
QUÉ SON LOS DATAFRAMES?
Es una estructura de datos bidimensional (filas y columnas) similar a una hoja de cálculo o tabla SQL. Posee filas, columnas y datos.
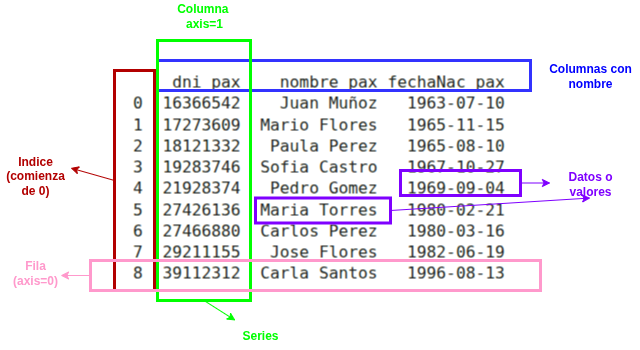
En la sección 1.4 se describen los métodos principales de los dataframes.
Vamos a ir por partes para ir mostrando como recuperar datos, organizarlos y guardarlos en un dataframe. Para poder crear el dataframe debemos determinar cuales son sus columnas, que en este caso son los nombres de los atributos de la tabla pasajero. Como vimos, cada columna es de tipo Series.
Vamos a recuperar el nombre de los atributos de la tabla que los debemos obtener del cursor. La lista creada datos_del_pasajero no posee las columnas, sino solo el resultado con las tuplas. Entonces, vamos a utilizar la propiedad description para recuperar esos nombres.
Propiedad description
La propiedad description de un cursor devuelve una lista de tuplas de este tipo (column_name, type, None, None, None, None, null_ok, column_flags).
Vemos qué devuelve la propiedad
cursor.description, donde el primer elemento de cada tupla posee el nombre de la columna:
for i in cursor.description:
print(i)
print(type(i[0]))
#columnas = [i[0] for i in cursor.description]
('dni_pax', 254, None, None, None, None, 0, 20483, 255)
<class 'str'>
('nombre_pax', 253, None, None, None, None, 0, 4097, 255)
<class 'str'>
('fechaNac_pax', 10, None, None, None, None, 0, 4225, 63)
<class 'str'>
Obtenemos los nombres de las columnas y los guardamos en un lista de columnas:
# Obtener nombres de columnas
columnas=[]
for i in cursor.description:
columnas.append(i[0])
columnas
['dni_pax', 'nombre_pax', 'fechaNac_pax']
Creamos un
dataframecon las columnas y el resultado de la consulta SQL. Mostramos las primeras 20 filas.
# Crear el dataframe con las filas de la consulta que fueron recuperadas y las columnas
df = pd.DataFrame(datos_del_pasajero, columns=columnas)
#Mostrar las primeras 20 filas del dataframe
print(df.head(20))
dni_pax nombre_pax fechaNac_pax
0 16366542 Juan Muñoz 1963-07-10
1 17273609 Mario Flores 1965-11-15
2 18121332 Paula Perez 1965-08-10
3 19283746 Sofia Castro 1967-10-27
4 21928374 Pedro Gomez 1969-09-04
5 27426136 Maria Torres 1980-02-21
6 27466880 Carlos Perez 1980-03-16
7 29211155 Jose Flores 1982-06-19
8 39112312 Carla Santos 1996-08-13
Cerrar la conexion:
cursor.close()
conexion.close()
Exportar a .csv#
Otra tarea que podemos hacer antes de terminar, es exportar el dataframe a un archivo .csv. En la sección 1.4 se describe completamente esta funcionalidad.
La creación del archivo .csv va a permitir tener el dataframe guardado en disco y reutilizarlo cuando sea necesario.
Algunos ejemplos de transformar el
dataframecon los datos del pasajero a un archivo llamadodatos_pasajeroXXX.csvson (crear una carpeta llamada archivosGenerados):
#con las opciones por defecto
df.to_csv('archivosGenerados/datospasajeroPorDefecto.csv')
# sin indice
df.to_csv('archivosGenerados/datospasajeroCambios.csv', index=False)
#sin indice y con separador entre datos
df.to_csv('archivosGenerados/datospasajeroCambios2.csv', index=False, sep='#')
# con indice y nombre de columnas que queremos incluir
df.to_csv('archivosGenerados/datospasajeroCambios3.csv', index=True, columns=['dni_pax', 'nombre_pax'])
# con formato de fecha aaaa/mm/dd
df.to_csv('archivosGenerados/datospasajeroCambios4.csv', date_format='%Y-%m-%d')
Ahora, HACEMOS TODO JUNTO dentro del
try-except:
conexion = None
cursor = None
try:
#Establecer la conexion
print("Conectando a MariaDB...")
conexion = mariadb.connect(**db_config)
print("Conexión exitosa!")
#Crear un cursor con la conexion
cursor = conexion.cursor()
print("\nSeleccionando datos...")
consulta = "SELECT * FROM pasajero"
#Ejecutar la consulta y gurdarla en un cursor
cursor.execute(consulta)
#Colocar a datos_del_pasajero el resultado de buscar todos los valores de la consulta
datos_del_pasajero = cursor.fetchall()
#print(datos_del_pasajero)
############### ACA USAMOS EL DATAFRAME ################
# Obtener nombres de columnas
columnas=[]
for i in cursor.description:
columnas.append(i[0])
# Crear el dataframe con las filas de la consulta que fueron recuperadas y las columnas
df = pd.DataFrame(datos_del_pasajero, columns=columnas)
#Mostrar las primeras 20 filas del dataframe
print(df.head(20))
# creamos un csv con las opciones por defecto
df.to_csv('archivosGenerados/datospasajeroPorDefecto.csv')
# Siempre se debe cerrar el cursor
cursor.close()
# Siempre se debe cerrar la conexion
conexion.close()
print("Conexión a MariaDB cerrada.")
except mariadb.Error as e:
print(f"Ocurrió un error :( {e}")
Conectando a MariaDB...
Conexión exitosa!
Seleccionando datos...
dni_pax nombre_pax fechaNac_pax
0 16366542 Juan Muñoz 1963-07-10
1 17273609 Mario Flores 1965-11-15
2 18121332 Paula Perez 1965-08-10
3 19283746 Sofia Castro 1967-10-27
4 21928374 Pedro Gomez 1969-09-04
5 27426136 Maria Torres 1980-02-21
6 27466880 Carlos Perez 1980-03-16
7 29211155 Jose Flores 1982-06-19
8 39112312 Carla Santos 1996-08-13
Conexión a MariaDB cerrada.