2.5. Integración y agregación#
Introducción#
Luego del análisis y limpieza individual de cada conjunto de datos debemos analizar si deseamos integrarlos entre ellos y realizar operaciones de agregación para resumir los datos. Generalmente estas tareas estan asociadas a los requerimientos del análisis.
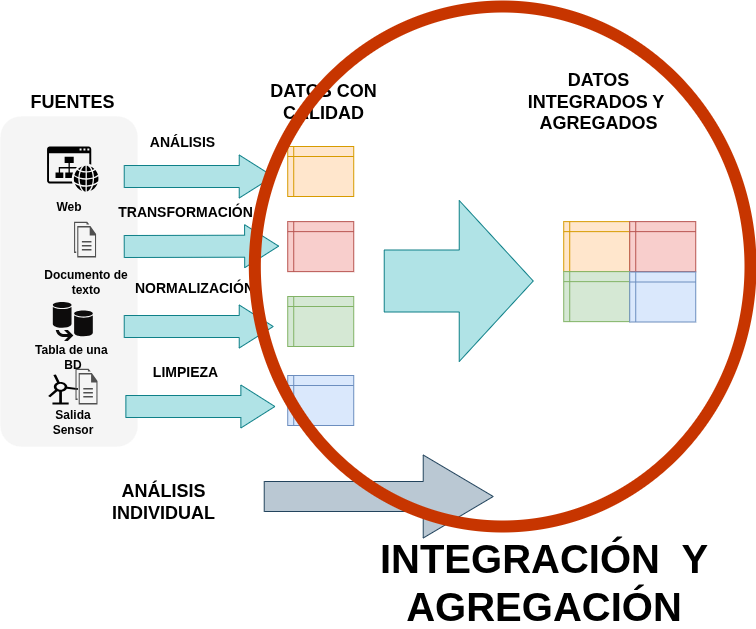
Integración de datos con concat()#
En Pandas existen dos formas generales de unir o mezclar dataframes que veremos en este curso, son concat() y merge().
MOMENTO CHEATSHEET
Este es el momento de recurrir a una nueva parte de la cheatsheet de Pandas para el método concat().
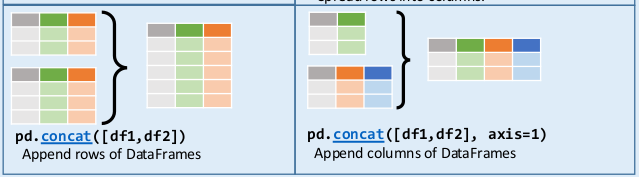
Método concat()
El método concat() permite concatenar filas (por defecto) o columnas. Algunas de sus opciones son:
objs: arreglo dedataframesoseriesa concatenar.axis: si debe concatenar filas o columnas:axis=0: apila las filas una debajo de la otra buscando por similitud de índice de columnas (nombres de columnas iguales)axis=1: concatena las columnas (una a continuación de otra) buscando por similitud de índice de filas (números de índices iguales)
join: la forma de manejar los índices:join='inner':con
axis=1: hace una intersección de índices de filas, es decir filas que coinciden en el índice las pone juntas y concatena las columnas. Elimina los índices que aparecen en sólo uno de losdataframes.con
axis=0: hace una intersección de columnas, dejando solo las columnas iguales y uniendo sus filas. Elimina las columnas que aparecen en sólo uno de losdataframes.
join='outer': es el valor por defecto y hace una unión total, es decir, mantiene todos los índices, aunque no coincidan. Cuando un valor no existe en undataframe, lo completa conNaN.
ignore_index: si esTrue, no se utilizan los valores de índice, es decir se va a etiquetar como 0,…, n-1. Por defecto esFalse.
La documentación completa de este método la podemos encontrar en pandas.concat
Ahora vamos a probar algunos ejemplos del uso de concat().
Vamos a crear un
dataframede ventas de un kiosko de Neuquén:
import pandas as pd
df_ventas_nqn = pd.DataFrame({
'id_cliente': [1, 2, 3, 4, 5, 6, 7],
'nombre': ['Susana', 'Oscar', 'Elena', 'Elena', 'Oscar', 'Elena', 'Lucila'],
'apellido': ['Horia','Acol', 'Morado', 'Morado','Acol','Morado', 'Nave'],
'ciudad': ['Neuquén', 'Rosario', 'Córdoba', 'Córdoba', 'Rosario', 'Córdoba', 'Plottier'],
'producto': ['Palitos de la Selva', 'Chupetín Pico Dulce', 'Rocklets', 'Alfajor Jorgito', 'Sugus', 'Tubby 4', 'Block'],
'precio': [100, 200, 150, 300, 120, 80, 230]
})
df_ventas_nqn
| id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|
| 0 | 1 | Susana | Horia | Neuquén | Palitos de la Selva | 100 |
| 1 | 2 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200 |
| 2 | 3 | Elena | Morado | Córdoba | Rocklets | 150 |
| 3 | 4 | Elena | Morado | Córdoba | Alfajor Jorgito | 300 |
| 4 | 5 | Oscar | Acol | Rosario | Sugus | 120 |
| 5 | 6 | Elena | Morado | Córdoba | Tubby 4 | 80 |
| 6 | 7 | Lucila | Nave | Plottier | Block | 230 |
Vamos a crear otro
dataframede ventas de un kiosko de Roca:
import pandas as pd
df_ventas_roca = pd.DataFrame({
'id_cliente': [5, 6, 7, 8, 9, 10, 11, 12],
'nombre': ['Marina', 'Carlos', 'Aquiles', 'Zacarias', 'Paloma', 'Elsa', 'Zoyla', 'Esteban'],
'apellido': ['Sierra', 'Perez Gil', 'Muestro', 'Flores', 'Blanca', 'Capunta', 'Vaca', 'Quito'],
'ciudad': ['Buenos Aires', 'Mendoza', 'Salta', 'Buenos Aires', 'La Plata', 'Mendoza', 'Bahía Blanca', 'La Rioja'],
'producto': ['Mogul', 'Chocolinas', 'Bon o Bon', 'Mogul', 'Chupetín Pico Dulce', 'Chocolinas', 'Chocolinas', 'Bazooka'],
'precio': [90, 250, 180, 210, 200, 150, 95, 56.9]
})
df_ventas_roca
| id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|
| 0 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 |
| 1 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 |
| 2 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 |
| 3 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 |
| 4 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 |
| 5 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 |
| 6 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 |
| 7 | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 |
Como vemos, ambos dataframes tienen la misma cantidad de columnas y son del mismo tipo.
Vamos a concatenar ambos
dataframespor filas y sin volver a indexar:
#concateno con las opciones por defecto
# no reinicia indice, hace outer y apila filas
df_comun = pd.concat([df_ventas_nqn,df_ventas_roca])
df_comun
| id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|
| 0 | 1 | Susana | Horia | Neuquén | Palitos de la Selva | 100.0 |
| 1 | 2 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200.0 |
| 2 | 3 | Elena | Morado | Córdoba | Rocklets | 150.0 |
| 3 | 4 | Elena | Morado | Córdoba | Alfajor Jorgito | 300.0 |
| 4 | 5 | Oscar | Acol | Rosario | Sugus | 120.0 |
| 5 | 6 | Elena | Morado | Córdoba | Tubby 4 | 80.0 |
| 6 | 7 | Lucila | Nave | Plottier | Block | 230.0 |
| 0 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 |
| 1 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 |
| 2 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 |
| 3 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 |
| 4 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 |
| 5 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 |
| 6 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 |
| 7 | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 |
Podemos observar que el índice empieza en 0..6 y luego vuelve a 0..7.
En cambio, si reorganizamos los índices, tenemos:
#concateno con
# reiniciar indices, hacer outer y apilar filas
df_comun = pd.concat([df_ventas_nqn,df_ventas_roca], ignore_index=True)
df_comun
| id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|
| 0 | 1 | Susana | Horia | Neuquén | Palitos de la Selva | 100.0 |
| 1 | 2 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200.0 |
| 2 | 3 | Elena | Morado | Córdoba | Rocklets | 150.0 |
| 3 | 4 | Elena | Morado | Córdoba | Alfajor Jorgito | 300.0 |
| 4 | 5 | Oscar | Acol | Rosario | Sugus | 120.0 |
| 5 | 6 | Elena | Morado | Córdoba | Tubby 4 | 80.0 |
| 6 | 7 | Lucila | Nave | Plottier | Block | 230.0 |
| 7 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 |
| 8 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 |
| 9 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 |
| 10 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 |
| 11 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 |
| 12 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 |
| 13 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 |
| 14 | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 |
Ahora si, el índice va del 1..14.
Vamos a probar la opcion
join='inner'y con las columnasaxis=1, es decir que concatene según el índice de fila:
#concateno con inner y columnas
# realiza una intersección de índices (`axis=1`) es decir busca índices iguales
df_comun = pd.concat([df_ventas_nqn,df_ventas_roca], join= 'inner', axis=1)
df_comun
| id_cliente | nombre | apellido | ciudad | producto | precio | id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Susana | Horia | Neuquén | Palitos de la Selva | 100 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 |
| 1 | 2 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 |
| 2 | 3 | Elena | Morado | Córdoba | Rocklets | 150 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 |
| 3 | 4 | Elena | Morado | Córdoba | Alfajor Jorgito | 300 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 |
| 4 | 5 | Oscar | Acol | Rosario | Sugus | 120 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 |
| 5 | 6 | Elena | Morado | Córdoba | Tubby 4 | 80 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 |
| 6 | 7 | Lucila | Nave | Plottier | Block | 230 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 |
Como podemos observar, concatenó (agregó) las columnas de df_ventas_roca a la izquierda según el índice en común. Esteban Quito en el índice = 7 no esta concatenado porque df_ventas_nqn no tienen ninguna fila con ese índice.
Vemos qué haría entonces el
join='outer':
#concateno con outer y columnas
df_comun = pd.concat([df_ventas_nqn,df_ventas_roca], join= 'outer', axis=1)
df_comun
| id_cliente | nombre | apellido | ciudad | producto | precio | id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | Susana | Horia | Neuquén | Palitos de la Selva | 100.0 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 |
| 1 | 2.0 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200.0 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 |
| 2 | 3.0 | Elena | Morado | Córdoba | Rocklets | 150.0 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 |
| 3 | 4.0 | Elena | Morado | Córdoba | Alfajor Jorgito | 300.0 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 |
| 4 | 5.0 | Oscar | Acol | Rosario | Sugus | 120.0 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 |
| 5 | 6.0 | Elena | Morado | Córdoba | Tubby 4 | 80.0 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 |
| 6 | 7.0 | Lucila | Nave | Plottier | Block | 230.0 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 |
| 7 | NaN | NaN | NaN | NaN | NaN | NaN | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 |
Como Esteban Quito en el índice = 7 no hace join con nadie, entonces lo agrega igualmente poniendo NaN en las columnas sin datos.
Ahora vamos a crear un nuevo
dataframeque posea dos columnas:
df_cantidades_roca = pd.DataFrame({
'id_cliente': [5, 6, 7, 8, 9, 10, 11, 12],
'cantidad': [2, 1, 5, 7, 8, 9, 3, 12]
})
df_cantidades_roca
| id_cliente | cantidad | |
|---|---|---|
| 0 | 5 | 2 |
| 1 | 6 | 1 |
| 2 | 7 | 5 |
| 3 | 8 | 7 |
| 4 | 9 | 8 |
| 5 | 10 | 9 |
| 6 | 11 | 3 |
| 7 | 12 | 12 |
Ahora queremos concatenar las ventas de Roca con las cantidades:
# join con columnas (`axis=0`), dejando solo las columnas con índices iguales.
#conserva todas las columnas porque es un outer
df_comun = pd.concat([df_ventas_roca,df_cantidades_roca], join= 'outer', axis=0)
df_comun
| id_cliente | nombre | apellido | ciudad | producto | precio | cantidad | |
|---|---|---|---|---|---|---|---|
| 0 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 | NaN |
| 1 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 | NaN |
| 2 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 | NaN |
| 3 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 | NaN |
| 4 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 | NaN |
| 5 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 | NaN |
| 6 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 | NaN |
| 7 | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 | NaN |
| 0 | 5 | NaN | NaN | NaN | NaN | NaN | 2.0 |
| 1 | 6 | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 2 | 7 | NaN | NaN | NaN | NaN | NaN | 5.0 |
| 3 | 8 | NaN | NaN | NaN | NaN | NaN | 7.0 |
| 4 | 9 | NaN | NaN | NaN | NaN | NaN | 8.0 |
| 5 | 10 | NaN | NaN | NaN | NaN | NaN | 9.0 |
| 6 | 11 | NaN | NaN | NaN | NaN | NaN | 3.0 |
| 7 | 12 | NaN | NaN | NaN | NaN | NaN | 12.0 |
Como vemos, este método sólo concatena (o mezcla índices), pero no hace un join como funcionaría en el lenguaje SQL. Entonces, cómo es un join verdadero? Siiii! con merge().
Integración de datos con merge()#
MOMENTO CHEATSHEET
Este es el momento de recurrir a una nueva parte de la cheatsheet de Pandas para el método merge(). Con este métdodo solo se pueden combinar 2 dataframes.
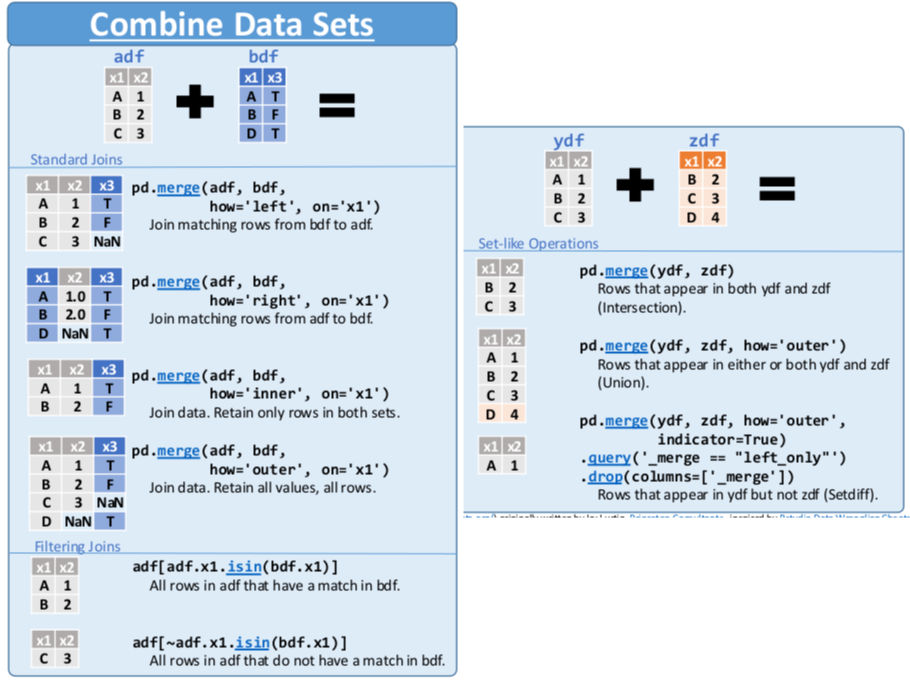
Este método permite hacer los joins de la misma manera que se hacen el SQL.
Por ejemplo, imaginemos que df_ventas_roca y df_cantidades_roca son tablas de una BD, para hacer un join entre ellas sobre la columna id_cliente, en SQL hacemos:
SELECT r.id_cliente, r.nombre, r.apellido, r.ciudad, r.producto, r.precio, c.cantidad FROM df_ventas_roca as r INNER JOIN df_cantidades_roca ON r.id_cliente = c.id_cliente
Esto mismo pero con
merge()es:
df_completo_roca = pd.merge(df_ventas_roca, df_cantidades_roca, how = 'inner', on = ['id_cliente'])
df_completo_roca
| id_cliente | nombre | apellido | ciudad | producto | precio | cantidad | |
|---|---|---|---|---|---|---|---|
| 0 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 | 2 |
| 1 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 | 1 |
| 2 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 | 5 |
| 3 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 | 7 |
| 4 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 | 8 |
| 5 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 | 9 |
| 6 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 | 3 |
| 7 | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 | 12 |
Opciones de merge()
Algunas de las opciones del método merge() son:
left:dataframedel lado izquierdoright:dataframedel lado derechohow: indica el tipo de join a realizar:'inner'(por defecto): solo filas con claves comunes en ambosdataframes'left': todas las filas deldataframeizquierdo, y las coincidentes del derecho. Se completa conNaN'right': todas las filas deldataframederecho, y las coincidentes del izquierdo. Se completa conNaN'outer': todas las filas de los dosdataframes. Se completa conNaN
on: arreglo de nombres de la/s columnas que deben hacer join. Si las columnas tienen nombres diferentes se debe usar left_on para decir el nombre d ela/s columnas deldataframede la izquiera y right_on con la/s columnas que deben hacer join deldataframede la derechasuffixes: se usa para diferenciar columnas con el mismo nombre en ambosdataframesque no forman parte del join. Si uno no quiere sufijos, deberían renombrarse las columnas. Si no se especifican sufijos, Pandas agrega por defecto los sufijos: _(‘_x’, ‘y’).
La documentación completa de este método la podemos encontrar en pandas.merge
Ahora vamos a hacer join entre
id_clientededf_ventas_nqnydf_ventas_roca:
#hacer un left join sobre id_cliente
df_comun = pd.merge(df_ventas_nqn, df_ventas_roca, how = 'left', on = ['id_cliente'])
df_comun
| id_cliente | nombre_x | apellido_x | ciudad_x | producto_x | precio_x | nombre_y | apellido_y | ciudad_y | producto_y | precio_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Susana | Horia | Neuquén | Palitos de la Selva | 100 | NaN | NaN | NaN | NaN | NaN |
| 1 | 2 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200 | NaN | NaN | NaN | NaN | NaN |
| 2 | 3 | Elena | Morado | Córdoba | Rocklets | 150 | NaN | NaN | NaN | NaN | NaN |
| 3 | 4 | Elena | Morado | Córdoba | Alfajor Jorgito | 300 | NaN | NaN | NaN | NaN | NaN |
| 4 | 5 | Oscar | Acol | Rosario | Sugus | 120 | Marina | Sierra | Buenos Aires | Mogul | 90.0 |
| 5 | 6 | Elena | Morado | Córdoba | Tubby 4 | 80 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 |
| 6 | 7 | Lucila | Nave | Plottier | Block | 230 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 |
Lo que podemos observar es que se renombran las columnas con nombres iguales, quedan todas las filas de df_ventas_nqn y solo los id_cliente 5, 6 y 7 hacen join, los demas se completan con NaN.
Agregación de datos#
La agregación es el mecanismo que permite combinar y resumir datos de forma tal que los mismos queden mas simples y manipulables para futuros análisis. Así como la integración, las tareas involucradas en la agregación responden principalmente a los objetivos del análisis, es decir se resumen de acuerdo a los requerimientos del sistema que se esta construyendo.
Para la agregación hay varios métodos que se pueden utilizar y generalmente estan asociados a las funciones de agregación y agrupamiento de SQL.
MOMENTO CHEATSHEET
Este es el momento de recurrir a una nueva parte de la cheatsheet de Pandas para conocer todos los métodos que nos permiten realizar agrupamientos y funciones.

Métodos que resumen datos#
En la primera parte de datos resumidos de la cheatsheet podemos observar métodos para calcular la cantidad de filas, columnas, tipos de datos, etc. Algunas de ellas ya las utilizamos en trabajos previos.
Vamos a probar algunas de ellas con
df_ventas_nqn:
# volvemos a listar df_ventas_nqn para ver que tenia
df_ventas_nqn
| id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|
| 0 | 1 | Susana | Horia | Neuquén | Palitos de la Selva | 100 |
| 1 | 2 | Oscar | Acol | Rosario | Chupetín Pico Dulce | 200 |
| 2 | 3 | Elena | Morado | Córdoba | Rocklets | 150 |
| 3 | 4 | Elena | Morado | Córdoba | Alfajor Jorgito | 300 |
| 4 | 5 | Oscar | Acol | Rosario | Sugus | 120 |
| 5 | 6 | Elena | Morado | Córdoba | Tubby 4 | 80 |
| 6 | 7 | Lucila | Nave | Plottier | Block | 230 |
# cantidad de filas de cada valor único, que sería lo mismo que agrupar por nombre
print(f'La cantidad de filas de los nombres de ventas de Neuquén es {df_ventas_nqn["nombre"].value_counts()}')
La cantidad de filas de los nombres de ventas de Neuquén es nombre
Elena 3
Oscar 2
Susana 1
Lucila 1
Name: count, dtype: int64
# cantidad de filas de cada valor único, que sería lo mismo que agrupar por nombre y apellido
# ver el uso de doble corchete
print(f'La cantidad de filas de los nombres de ventas de Neuquén es {df_ventas_nqn[["nombre","apellido"]].value_counts()}')
La cantidad de filas de los nombres de ventas de Neuquén es nombre apellido
Elena Morado 3
Oscar Acol 2
Lucila Nave 1
Susana Horia 1
Name: count, dtype: int64
# tamaño de ventas
print(f'El DF es una estructura de (filas,columnas): {df_ventas_nqn.shape}')
El DF es una estructura de (filas,columnas): (7, 6)
# el tipo de datos de cada columna
# ojo, sin parentesis
print(f'El tipo de datos de cada columna: \n{df_ventas_nqn.dtypes}')
El tipo de datos de cada columna:
id_cliente int64
nombre object
apellido object
ciudad object
producto object
precio int64
dtype: object
# resumen del dataframe, similar al anterior pero mas completo
df_ventas_nqn.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7 entries, 0 to 6
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id_cliente 7 non-null int64
1 nombre 7 non-null object
2 apellido 7 non-null object
3 ciudad 7 non-null object
4 producto 7 non-null object
5 precio 7 non-null int64
dtypes: int64(2), object(4)
memory usage: 468.0+ bytes
Un caso particular y bastante completo es el método describe() que devuelve un resumen estadístico de las columnas de un dataframe.
Para columnas numéricas devuelve: count (cantidad de valores no nulos), mean (media aritmética), std (desviación estándar), min (valor mínimo), 25% (primer cuartil - Q1), 50% (mediana - Q2), 75% (tercer cuartil - Q3), y max (valor máximo).
Para columnas categóricas devuelve: count (cantidad de valores no nulos), unique (cantidad de valores únicos), top (valor que mas se repite), y freq (las veces que aparece el valor de top).
# resumen estadístico de las columnas numéricas de un `dataframe`
df_ventas_nqn.describe()
| id_cliente | precio | |
|---|---|---|
| count | 7.000000 | 7.000000 |
| mean | 4.000000 | 168.571429 |
| std | 2.160247 | 78.830741 |
| min | 1.000000 | 80.000000 |
| 25% | 2.500000 | 110.000000 |
| 50% | 4.000000 | 150.000000 |
| 75% | 5.500000 | 215.000000 |
| max | 7.000000 | 300.000000 |
# resumen estadístico de TODAS las columnas de un `dataframe`
df_ventas_nqn.describe(include='all')
| id_cliente | nombre | apellido | ciudad | producto | precio | |
|---|---|---|---|---|---|---|
| count | 7.000000 | 7 | 7 | 7 | 7 | 7.000000 |
| unique | NaN | 4 | 4 | 4 | 7 | NaN |
| top | NaN | Elena | Morado | Córdoba | Palitos de la Selva | NaN |
| freq | NaN | 3 | 3 | 3 | 1 | NaN |
| mean | 4.000000 | NaN | NaN | NaN | NaN | 168.571429 |
| std | 2.160247 | NaN | NaN | NaN | NaN | 78.830741 |
| min | 1.000000 | NaN | NaN | NaN | NaN | 80.000000 |
| 25% | 2.500000 | NaN | NaN | NaN | NaN | 110.000000 |
| 50% | 4.000000 | NaN | NaN | NaN | NaN | 150.000000 |
| 75% | 5.500000 | NaN | NaN | NaN | NaN | 215.000000 |
| max | 7.000000 | NaN | NaN | NaN | NaN | 300.000000 |
Funciones de agregación y uso de groupby() y agg()#
En la parte inferior del cheatsheet se pueden obervar las funciones de agregación que permiten hacer cálculos sobre un conjunto de datos determinado. Entre ellas tenemos sum(), count(), min(), max(), etc. Cuando las utilizamos solas, hacen los cálculos sobre el conjunto de datos completo.
Por ejemplo, volvemos a listar
df_completo_roca:
df_completo_roca
| id_cliente | nombre | apellido | ciudad | producto | precio | cantidad | |
|---|---|---|---|---|---|---|---|
| 0 | 5 | Marina | Sierra | Buenos Aires | Mogul | 90.0 | 2 |
| 1 | 6 | Carlos | Perez Gil | Mendoza | Chocolinas | 250.0 | 1 |
| 2 | 7 | Aquiles | Muestro | Salta | Bon o Bon | 180.0 | 5 |
| 3 | 8 | Zacarias | Flores | Buenos Aires | Mogul | 210.0 | 7 |
| 4 | 9 | Paloma | Blanca | La Plata | Chupetín Pico Dulce | 200.0 | 8 |
| 5 | 10 | Elsa | Capunta | Mendoza | Chocolinas | 150.0 | 9 |
| 6 | 11 | Zoyla | Vaca | Bahía Blanca | Chocolinas | 95.0 | 3 |
| 7 | 12 | Esteban | Quito | La Rioja | Bazooka | 56.9 | 12 |
Listamos la suma total vendida en todo el
dataframe:
# la suma total vendida es
print(f'La suma total vendida es: {df_completo_roca["precio"].sum()}')
La suma total vendida es: 1231.9
Sin embargo, cuando queremos aplica una función de agregación a grupos de datos, debemos utilizar el groupby(), el cual arma grupos y aplica la función a cada uno de ellos. Funciona igual que el GROUP BY de SQL.
En el ejemplo siguiente agrupamos por ciudad (ciudades iguales) y aplicamos
sum()a cada uno de los grupos para sumar el precio:
# agrupo por ciudad, sumo los precios
# ver que precio tiene doble [[]], de esa manera se devuelve un DF
# si [precio] devuelve una serie
df_completo_roca.groupby(["ciudad"])[["precio"]].sum()
| precio | |
|---|---|
| ciudad | |
| Bahía Blanca | 95.0 |
| Buenos Aires | 300.0 |
| La Plata | 200.0 |
| La Rioja | 56.9 |
| Mendoza | 400.0 |
| Salta | 180.0 |
Ahora agrupamos por ciudad y producto y a cada grupo sumamos las catidades:
#agrupo por ciudad y producto, sumo las cantidades
# ver que cantidad tiene doble [[]], de esa manera se devuelve un DF
# si [cantidad] devuelve una serie
resultado = df_completo_roca.groupby(["ciudad","producto"])[["cantidad"]].sum()
resultado
| cantidad | ||
|---|---|---|
| ciudad | producto | |
| Bahía Blanca | Chocolinas | 3 |
| Buenos Aires | Mogul | 9 |
| La Plata | Chupetín Pico Dulce | 8 |
| La Rioja | Bazooka | 12 |
| Mendoza | Chocolinas | 10 |
| Salta | Bon o Bon | 5 |
Un caso diferente es el uso del método agg() ya que permite aplicar una o varias funciones de agregación a columnas de un groupby o directamente a un dataframe.
Vemos ejemplos del uso de
agg():
# calculo la suma total y la cantidad de tuplas de cantidad
# y solo la suma de todos los precios
resultado = df_completo_roca.agg({
'cantidad': ['sum','count'],
'precio': ['sum']})
resultado
| cantidad | precio | |
|---|---|---|
| sum | 47 | 1231.9 |
| count | 8 | NaN |
Si ahora queremos renombrar el resultado de una función de agregación, podemos también usar agg.
Renombramos a cantidadVendida la cantidad vendida de cada producto:
# agrupo por producto, sumo las cantidades vendidas de cada uno
# y renombro la columna de la suma a 'cantidadVendida'
resultado = df_completo_roca.groupby(['producto']).agg(
cantidadVendida = ('cantidad', 'sum')
)
resultado
| cantidadVendida | |
|---|---|
| producto | |
| Bazooka | 12 |
| Bon o Bon | 5 |
| Chocolinas | 13 |
| Chupetín Pico Dulce | 8 |
| Mogul | 9 |
Por último con el métdodo
query()podemos hacer aplicar condiciones sobre la respuesta de la función de agregación y elgroupby():
# agrupo por producto, sumo las cantidades vendidas de cada uno
# y renombro la columna de la suma a 'cantidadVendida'
# por ultimo con query(), filtro por la cantidadVendida a sólo las mayores a 10
resultado = (df_completo_roca.groupby(['producto'])
.agg(cantidadVendida = ('cantidad', 'sum'))
).query('cantidadVendida >10')
resultado
| cantidadVendida | |
|---|---|
| producto | |
| Bazooka | 12 |
| Chocolinas | 13 |